
24人团队硬刚英伟达!AMD前高管梦之队出手,新芯片每秒17000个token
24人团队硬刚英伟达!AMD前高管梦之队出手,新芯片每秒17000个token刚刚推出的一款最新芯片,直接冲上硅谷热榜。峰值推理速度高达每秒17000个token。什么概念呢?当前公认最强的Cerebras,速度约为2000 token/s。 速度直接快10倍,同时成本骤减20倍、功耗降低10倍。
来自主题: AI资讯
9695 点击 2026-02-22 01:21
 搜索
搜索
刚刚推出的一款最新芯片,直接冲上硅谷热榜。峰值推理速度高达每秒17000个token。什么概念呢?当前公认最强的Cerebras,速度约为2000 token/s。 速度直接快10倍,同时成本骤减20倍、功耗降低10倍。

近年来,众多原告——包括书籍、报纸、计算机代码和照片的出版商——起诉人工智能公司使用受版权保护的材料来训练模型。所有这些诉讼中的一个关键问题是,人工智能模型如何轻易地从原告的受版权保护的内容中逐字摘录。

Meta推出KernelLLM,这个基于Llama 3.1微调的8B模型,竟能将PyTorch代码自动转换为高效Triton GPU内核。实测数据显示,它的单次推理性能超越GPT-4o和DeepSeek V3,多次生成时得分飙升。
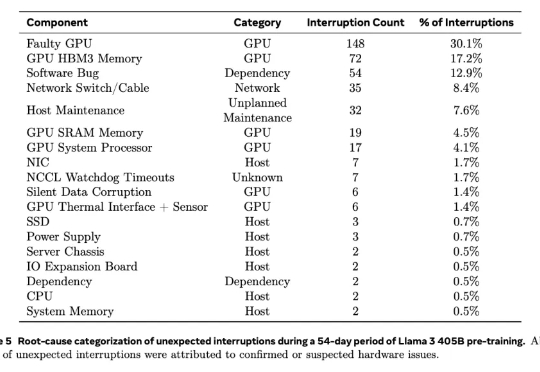
根据去年2024年7月28日Meta公司在训练大模型(Llama 3)时使用“16384 个 英伟达H100 GPU 集群”的经验,该显卡在高负载、大规模集群运行环境下容易出现以下故障点:
最近,AI 公司 Databricks 推出了一种新的调优方法 TAO,只需要输入数据,无需标注数据即可完成。更令人惊喜的是,TAO 在性能上甚至超过了基于标注数据的监督微调。
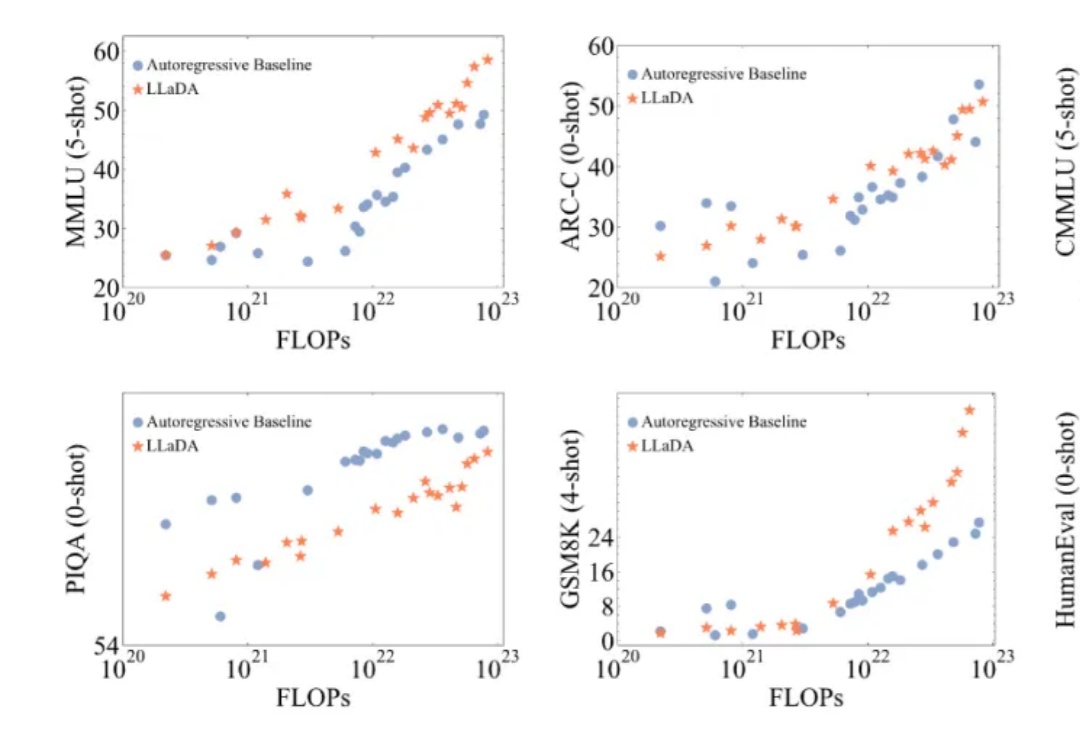
近年来,大语言模型(LLMs)取得了突破性进展,展现了诸如上下文学习、指令遵循、推理和多轮对话等能力。目前,普遍的观点认为其成功依赖于自回归模型的「next token prediction」范式。

2024年11月,艾伦人工智能研究所(Ai2)推出了Tülu 3 8B和70B,在性能上超越了同等参数的Llama 3.1 Instruct版本,并在长达82页的论文中公布其训练细节,训练数据、代码、测试基准一应俱全。
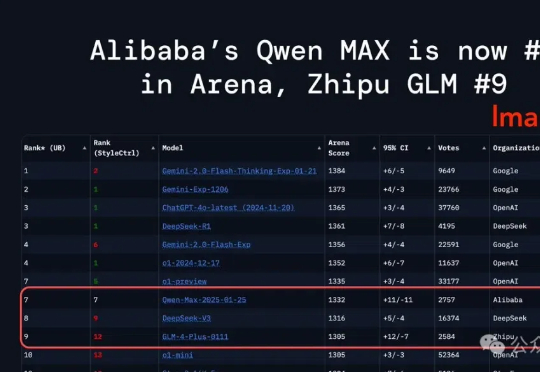
刚刚,大模型竞技场榜单上再添一款国产模型——来自阿里,Qwen2.5-Max,超越了DeepSeek-V3,以总分1332的成绩位列总榜第七。同时还一举超越Claude 3.5 Sonnet、Llama 3.1 405B等模型。

2024又是AI精彩纷呈的一年。LLM不再是AI舞台上唯一的主角。随着预训练技术遭遇瓶颈,GPT-5迟迟未能问世,从业者开始从不同角度寻找突破。以o1为标志,大模型正式迈入“Post-Training”时代;开源发展迅猛,Llama 3.1首次击败闭源模型;中国本土大模型DeepSeek V3,在GPT-4o发布仅7个月后,用 1/10算力实现了几乎同等水平。

因为 V3 版本开源模型的发布,DeepSeek 又火了一把,而且这一次,是外网刷屏。 训练成本估计只有 Llama 3.1 405B 模型的 11 分之一,后者的效果还不如它。